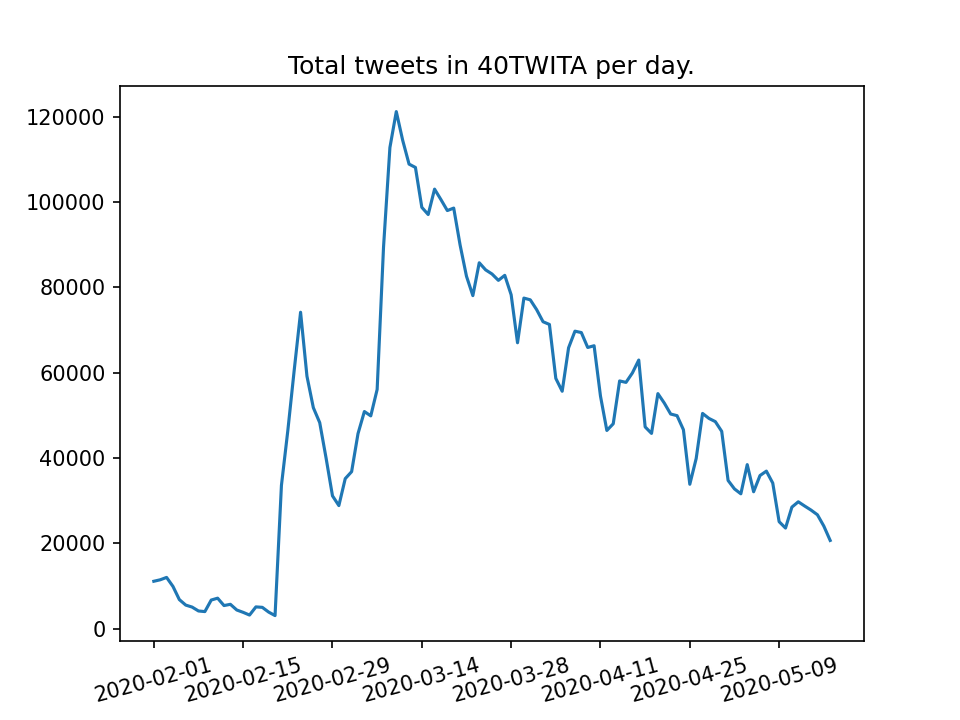
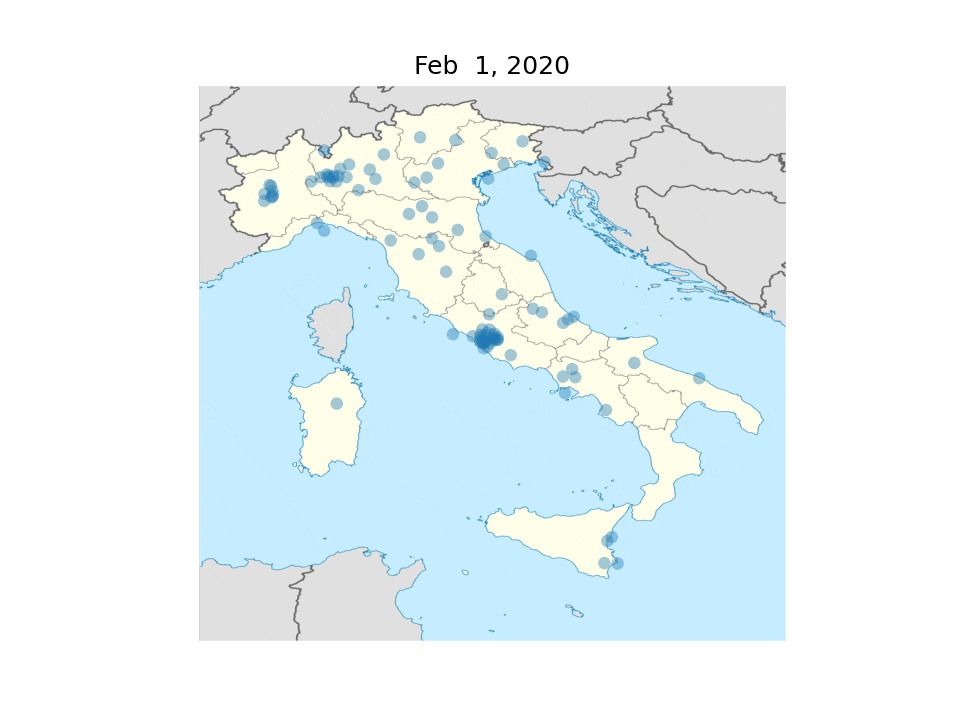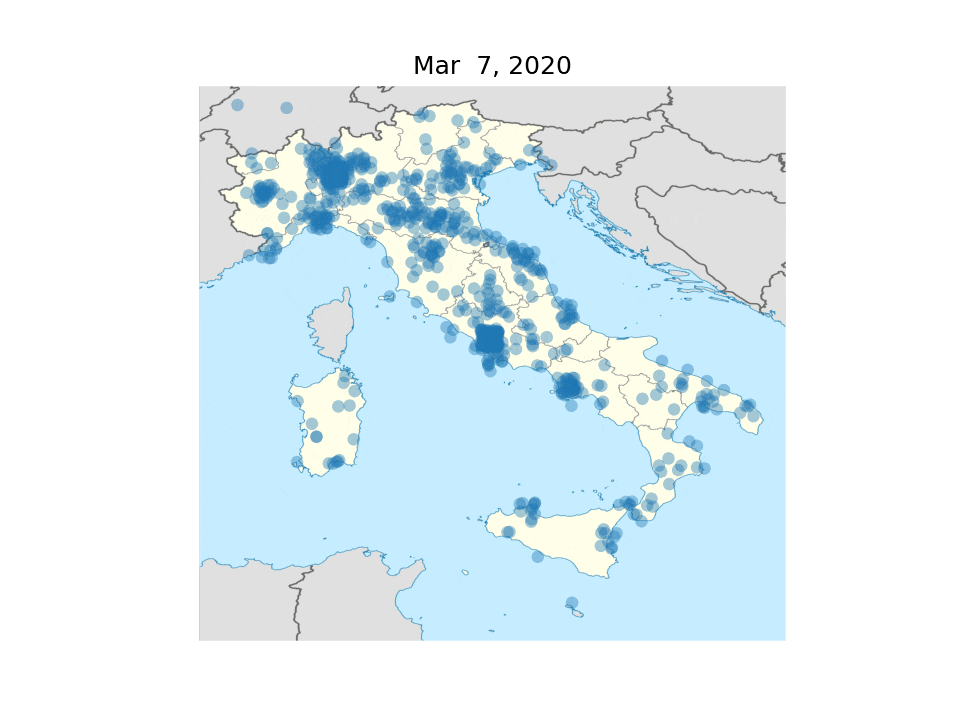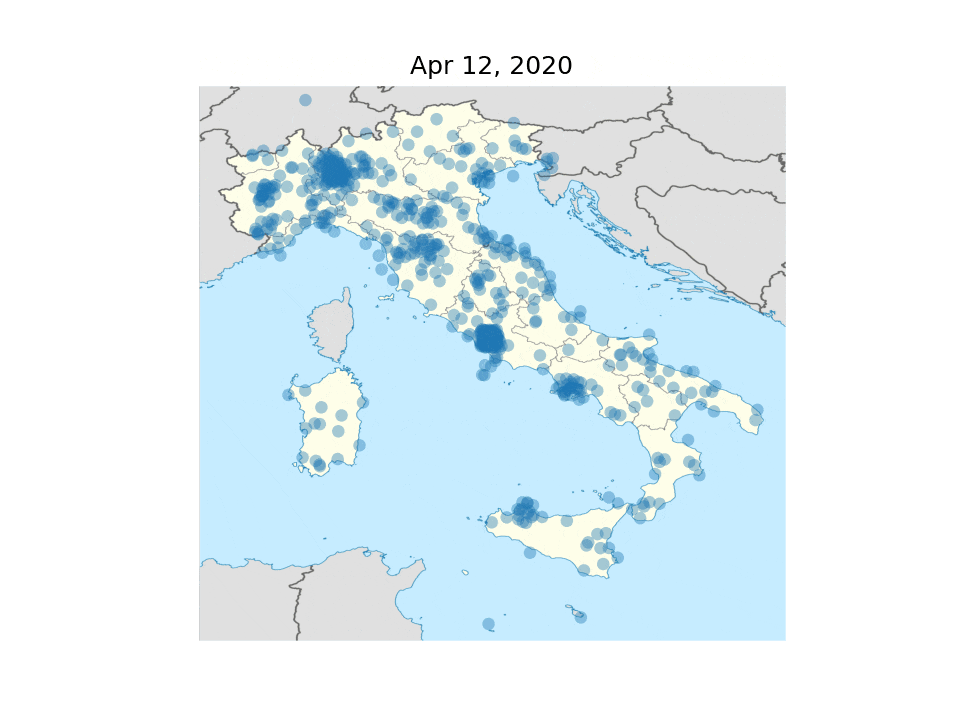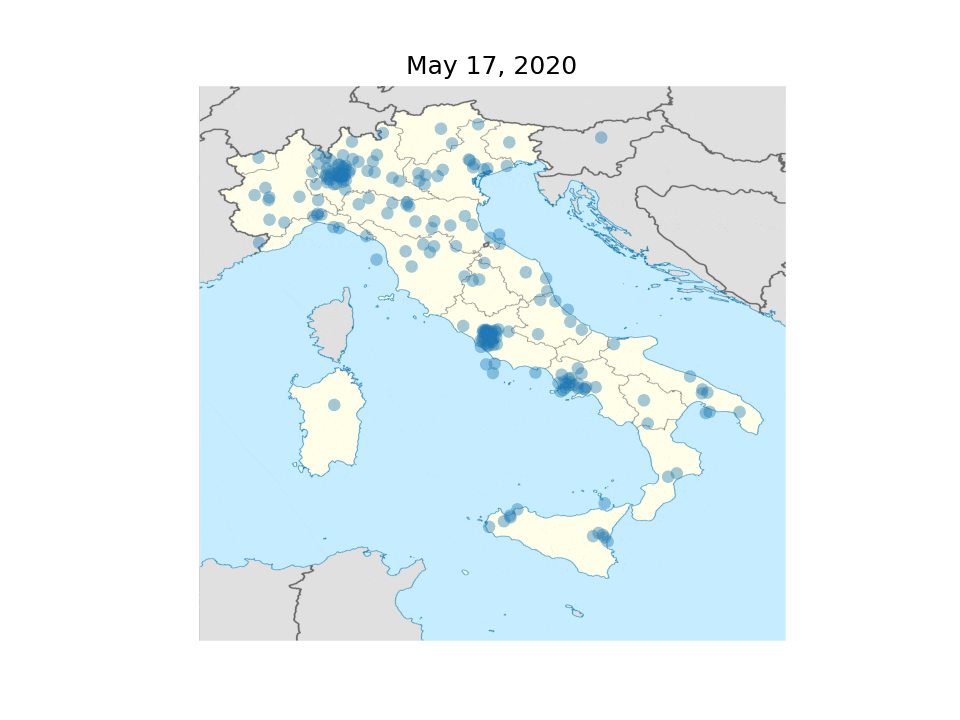
The COVID-19 pandemic of 2020, as any worldwide catastrophic event, generate a substantial amount of online discourse on social media. The quantity of infomration and opinions expressed in natural language on platforms like Twitter and Facebook is such that computational methods are required to compile a representative corpus. In turn, computational linguistic techniques can be used on these data to track events, opinions, emotions, and the spread of information on the social network. Furthermore, a large-scale resource of social media data on the topic of the pandemic can help build tools to monitor, and possibly prevent, undesirable phenomena that are already being observed, such as hate speech towards non-traditional targets (e.g., chinese people in Italy) and the spread of fake news. Italy was one of the first countries to be hit by the COVID-19 pandemic, and is among the most suffering in terms of cotagion and losses (about 32k reported deaths as of May 19, 2020). Therefore, tracking the online discourse in Italy is particularly relevant. 40wita is a corpus of social media data about the COVID-19 pandemic and safety measures in Italy. The collection comprises hudreds of thousands messages from Twitter in the Italian language, collected daily from TWITA, the main corpus of Italian Twitter at the University of Turin. The tweets for 40wita are filtered from TWITA with a list of carefully chosen keywords designed to capture the online discourse about COVID-19 with high precision. Overall, we collected over five million tweets from February 1st, 2020, with peaks at 120k tweets in one day (the highest peak is on March 10, the day lockdown measures started in Italy). Together with the tweet texts, the corpus include metadata such as the geolocalization, user screenname, timestamp, and links to the original data structure as provided by the Twitter API. The dataset is being made available for research purposes and it has already been downloaded by scholars worldwide. 40wita is developed in collaboration with Dr. Tommaso Caselli at the University of Groningen, Netherlands. The dataset is described at available at twita.di.unito.it.
Tweets per day in the 40wita corpus. Notable peaks corresponds to particular events, such as the first case reported in Italy in February, and the start of lockdown measures on March 10.
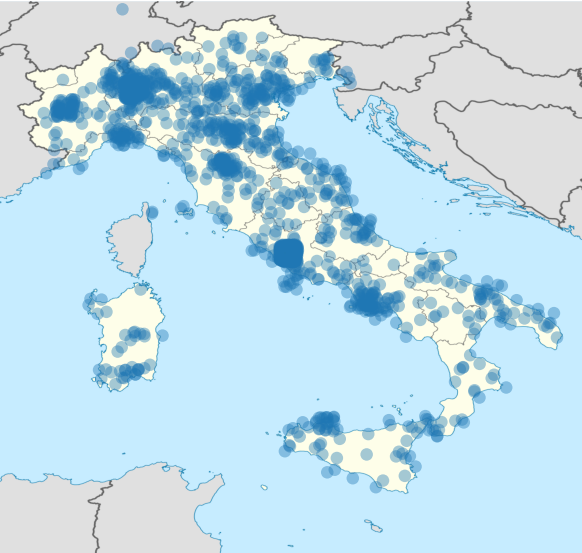
Daily tweets with geolocalization from 40wita. Each dot represents a tweet.